


近日,核工业西南物理研究院(简称“西物院”)团队在人工智能与可控核聚变交叉领域取得重要突破,构建出一款针对聚变领域的预训练模型——“曦元(FusionMAE)”,实现了缺失诊断数据自动补全、二级数据自动分析、相似实验现象检索、下游AI4Fusion模块性能提升等功能,成功演示了一种将大模型技术应用于磁约束核聚变领域的全新技术范式,体现出作为“基座模型”的重大潜力。

相关研究成果以《FusionMAE, a self-supervised pretrained model to optimize and simplify diagnostic and control of fusion plasma》为题,发表在Nature旗下的物理学Q1期刊《Communications Physics》上,这是“曦元”大模型自2025年7月作为国资委首批中央企业人工智能战略性高价值场景发布后,首次在国际学术界得到评审认证。
等离子体诊断数据缺失长期困扰核聚变研究,尤其在超高温、强中子辐照的聚变堆环境中更为严峻,这会极大地影响装置的安全稳定运行。“曦元”大模型利用等离子体各物理参数间的耦合关系,对失效和缺失数据进行智能补全。测试显示,模型在单通道缺失时的补全准确率达到97.2%,整个诊断阵列缺失时的补全准确率达到94.5%。从而为未来聚变堆提出了一种“虚拟备用诊断”的技术方案,为聚变堆7×24小时的连续运行提供了重要保障。
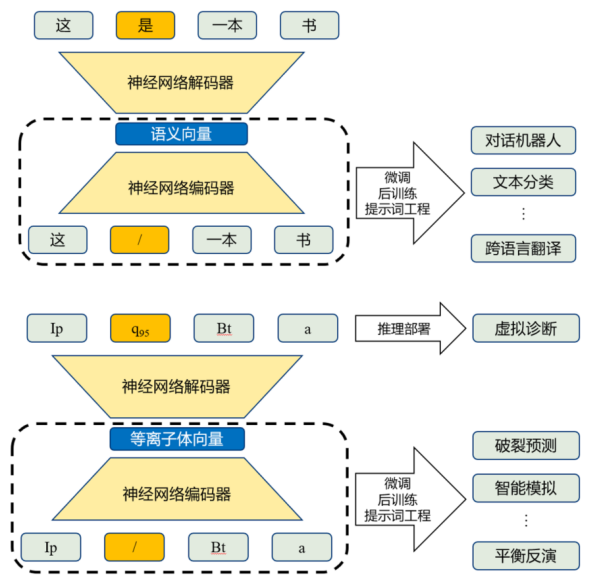
曦元大模型(下)借鉴大语言模型(上)的研发思路,通过通用的预训练与针对任务的微调/后训练/提示词工程等方式,解决多场景问题
曦元大模型也进一步赋能了多个下游任务场景。在二级数据自动分析中,将平衡位形、不稳定性幅值等二级数据视为“缺失诊断”,由模型进行补全,从而替代人工分析过程;在控制模块性能优化方面,以等离子体向量作为通用输入,支撑平衡反演、演化预测与破裂预测等模块运行,为各模块带来显著性能提升;此外,在相似实验现象检索中,等离子体向量会自发将物理性质接近的等离子体投影至高维空间中的近邻点,进而支撑快速检索相似实验现象。
除中国环流三号外,曦元大模型也在球形托卡马克SUNIST-2上验证了这一方法的跨装置通用性,并正在国外的聚变装置上开展联合验证。
免责声明:本网转载自合作媒体、机构或其他网站的信息,登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。本网所有信息仅供参考,不做交易和服务的根据。本网内容如有侵权或其它问题请及时告之,本网将及时修改或删除。凡以任何方式登录本网站或直接、间接使用本网站资料者,视为自愿接受本网站声明的约束。
