


AI技术的应用,短短几年内节省了数千万美元,这只是从覆盖国内所有核电站运营的数千TB字节数据中发现隐藏宝藏的开始。
1、用AI激励换料设计

2017年,蓝波(Blue Wave)AI实验室和Constellation(前身为Exelon Generation)开始合作,应用植根于AI的技术来解决其中一些核能问题。
Constellation运营着美国最大的核电站(8个发电站有14台BWR,4个发电站有7台压水堆(PWR)),因此拥有大量与这些关键挑战相关的设计、性能和运行数据。
特别是MCO和特征值的可预测性问题是第一个被解决的问题,这两个问题的解决方案正在被整合到Constellation的重新加载设计过程中。
核能机器学习
首先,机器学习是AI的一个分支,它可以提取复杂问题的答案,这些问题可能通过更传统的方法难以解决。
当大量数据可用于分析技术问题,或分析基于物理的模型无法解决的异常复杂的非线性问题时,AI尤其有用。
ML中有许多分支,大致可分为几类:
监督学习;
回归——用于预测连续变量的回归,如给定反应堆状态点的热极限、MCO或有效性;
分类——用于将元素分配到多个类别(例如,通过确定诊断健康状态进行设备监控);
无监督学习——用于聚类、异常检测、降维和特征工程。
ML的基础是普适逼近定理,该定理保证,如果满足某些直接条件,人工神经网络可以以任意精度表示真函数F(x)。更重要的是存在足够的数据分布,其分布近似于目标系统的预期分布。
试验数据是用于推断该函数的数据集,由许多历史观测数据组成。函数的输入或原始特征是反应堆的状态点x→i给定时刻,而目标是真函数的相应输出,yi=F(x→i)。
MCO测量、在线特征值或热极限是上述三个问题的试验目标。
从根本上说,反应堆状态点是完整描述给定时刻堆芯状态所需的所有信息的集合。
在实践中,我们必须依赖通过测量、设计、设定点或模拟已知的有限信息。
例如,运行参数的测量,如热功率和堆芯流量、控制棒模式加上切口、燃料和晶格设计,以及堆芯模拟器的大量输出,共同构成了堆芯的近似表示。
通过足够的观察(x→i、yi),控制一个过程的基本功能是可以学习的。
2、关于数据

回到刚刚的问题,每两年的燃料循环包含数百个每日反应堆状态点。
虽然每个循环可能包含数百个点,但在一个方面,燃料循环本身可以被视为一个正式点,将与该设计堆芯有关的所有信息编入规定。
因此,将来自多个燃料循环的数据汇集到试验集中,以了解完整的功能动态至关重要。
对于多个反应堆现场,如果预期基础功能相似,则可能会合并来自每个机组的数据。
Constellation的大部分沸水反应堆都有六到八个燃料循环的数据,虽然这看起来可能很多(总计数万个数据点),但ML的典型应用,如图像识别,需要数百万个训练样本。
已经采用了许多技术来增强数据集,包括用于维持预期分布的数据增强、训练目标的插值,以及最大限度地利用来自多个站点信息的转移学习。
这些技术使高精度模型的开发扩展到拥有比其他情况下所需数据更少的反应堆成为可能。
另一个需要克服的挑战是需要哪些输入。在核能等非常专业的领域,这往往成为采用AI的主要障碍。
一个纯粹的数据科学家可能会以“投入越多越好”的态度来处理这个问题
但是,当输入的数量与试验示例的数量相匹配或超过时,这种观点就行不通了。
在这里,输入特征空间由来自堆芯模拟器的数万个束和节点输出、数十万个逐针燃料属性和数十个全局反应堆变量组成。
如果不受约束,所有这些信息都可以用来训练一个试验误差精确为零、预测能力绝对为零的模型!它的效用在哪里?
太多的变量和太多的试验会导致模型只对试验集有用,而不是更一般的情况。
当这种情况发生时,模型已经拟合了数据中的噪声,掩盖了潜在的功能动态学,并且该模型被称为过度拟合。
同样,模型结构的复杂性(例如神经元的数量)也会导致过度拟合的可能性。
当一个模型在新的情况下(例如,新的燃料循环)继续表现良好时,它被称为“泛化”良好。
泛化意味着模型能够很好地捕捉到控制过程的潜在动态,并且在锁定数据中的随机噪声之前停止试验过程。
诀窍是在(1)输入特征空间的大小和性质和(2)模型体系结构、建模方法之间找到平衡,并仔细验证方法,以获得最具普遍性的模型。
对于MCO来说,答案是通过特征工程和对底层机制的物理理解,将输入特征空间缩减为MCO关键驱动因素的“规范集”。
在这样做的过程中,输入特征空间被缩减为几十个关键变量,以捕捉MCO的动态。
这使我们能够开发具有操作员可以控制的参数的模型,使模型不仅具有预测能力,而且同样重要的是具有纠正能力。
对于特征值,成功的方法更多地依赖于模型架构的性质,同时保留构成反应堆状态点的大量输入特征集合。
通过巧妙地将每个状态点转换为通过曝光、空洞、功率等各种“过滤器”查看的反应堆堆芯的三维图像,我们开发了一种卷积神经网络架构,该架构已被证明在图像识别和自然语言处理等任务中非常有效。
3、预测能力
BWR堆芯内束参数的可视化.
与任何创新一样,结果是其价值或效用的最终仲裁者。
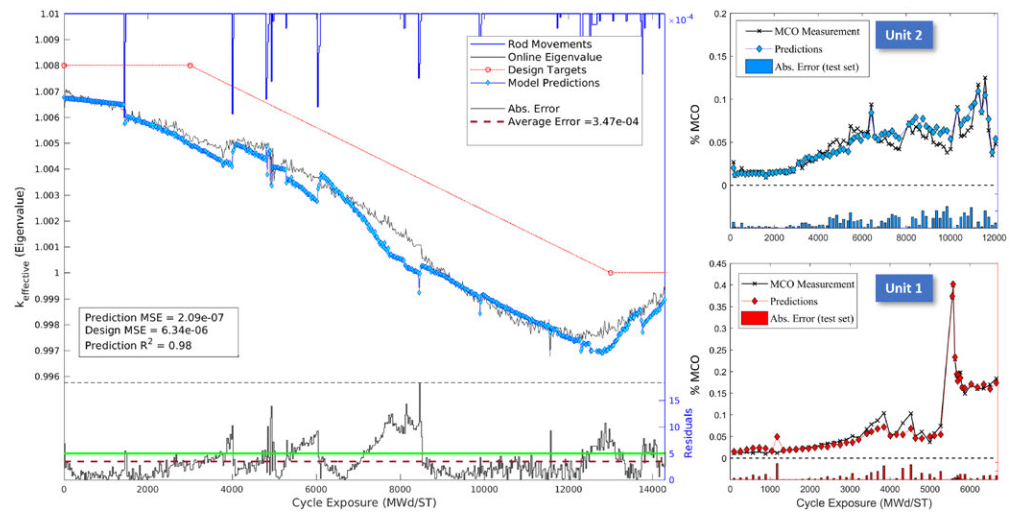
对于MCO,这种预测能力的一个例子在下面的图表中进行了说明,其中模型预测与两个Constellation单元的MCO测量值进行了叠加。
在这里,模型预测是从整个周期收集的风险计算中获得的。
自模型首次部署以来,在过去三年中,该站的平均预测误差为±0.018% MCO。
这种特殊的性能水平现在仅受到MCO测量不确定度施加的分辨率的限制。采用这一技术的另外10台BWR也获得了类似的精确度。
图中还显示,与当前实践状态相比,特征值模型性能表明,预测不确定性降低了四倍,平均误差小于±0.0005。
此外,这一性能水平可在整个BWR机组中扩展,当新燃料类型引入堆芯时,模型结构的最新进展显示出明显的弹性恢复能力。
从重新装载设计到周期管理的无缝集成
这些基于AI的预测算法已经变成了基于云计算平台MCO.ai和特征值.ai,现在完全集成到重新加载过程中。
核心设计的每一次迭代(有很多次迭代)都可以通过平台运行,以评估设计关于MCO和特征值趋势的影响。
核心设计人员可以在他们的办公桌上随意规划场景,并探索组合规格、重新装载批量、装载模式、反应性控制策略等数百个选项。
这些预测模型是根据堆芯条件和堆芯模拟器输出得出的输入特征构建的,所有这些特征都可以在重新加载设计过程的早期阶段进行预测。
因此,这些工具采用这些堆芯预测,并在燃料循环开始前一年,为堆芯设计师提供MCO和特征值行为的可靠预测。
通过这种方式,可以优化换料堆芯设计,以减少换料批量和/或浓缩,将MCO降低到规定限值以下,并确保通过更可靠的特征值预测满足能源需求。
这些新功能不仅限于核心设计,同样的概念也适用于周期管理战略评估。
如果发生与计划运行策略相关的不可预见的变化,如燃料故障、计划外停机或启动延迟,则可利用此预测套件分析替代运行场景,并提供用户友好的比较。
事实上,2019年一座BWR出现了燃料缺陷,需要在整个循环结束时插入功率抑制控制棒,两个完全插入的控制棒导致MCO比正常情况下大规模增长——MCO从0.05%发生阶跃变化到0.4%,在前(该模型以较高的精度预测)单元1 MCO图中可以看到。
这就提出了一个问题,即在达到不可接受的高MCO水平之前,是否需要在循环中停堆以消除燃料缺陷。
利用MCO.ai,设计了一种运行策略,以在周期结束前将MCO水平保持在程序限制以下,从而避免代价高昂的停机(超过600万美元)
4、优势发展
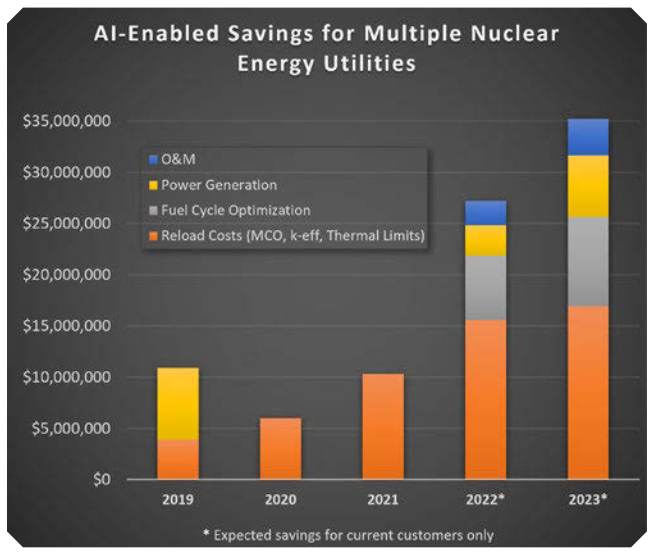
通过与蓝波AI实验室的合作,Constellation在其BWR的两个长期待解决问题上取得了突破性进展,实现了操作的可预测性。
将ML与堆芯设计和循环管理流程结合使用,可降低燃料成本,降低电厂剂量率,保护电厂资产,避免发电收入损失,并减少返工,从而为业务带来回报。
蓝波AI实验室和Constellation正凭借这些进步引领行业,并正在寻求其他应用,以改善核电运行和经济性,短短几年内节省了数千万美元,这只是从覆盖国内所有核电站运营的数千TB字节数据中发现隐藏宝藏的开始。
蓝波和Constellation正致力于将这些技术应用于许多领域,解决其他高价值问题,其中包括更精确的热极限计算、虚拟校准和测量,以及电厂部件的剩余寿命,以实现基于真实状态的维护策略。
最后,这些见解中的大部分,如对传感器类型和数量问题的方案,将应用于下一代电厂设计。核工业即将成为无碳能源的天然支柱,AI将加速这一提升,并在一个新的水平上提供更大的发展优势,我相信这也仅仅只是个开始。
免责声明:本网转载自合作媒体、机构或其他网站的信息,登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。本网所有信息仅供参考,不做交易和服务的根据。本网内容如有侵权或其它问题请及时告之,本网将及时修改或删除。凡以任何方式登录本网站或直接、间接使用本网站资料者,视为自愿接受本网站声明的约束。
